

Case Study Details
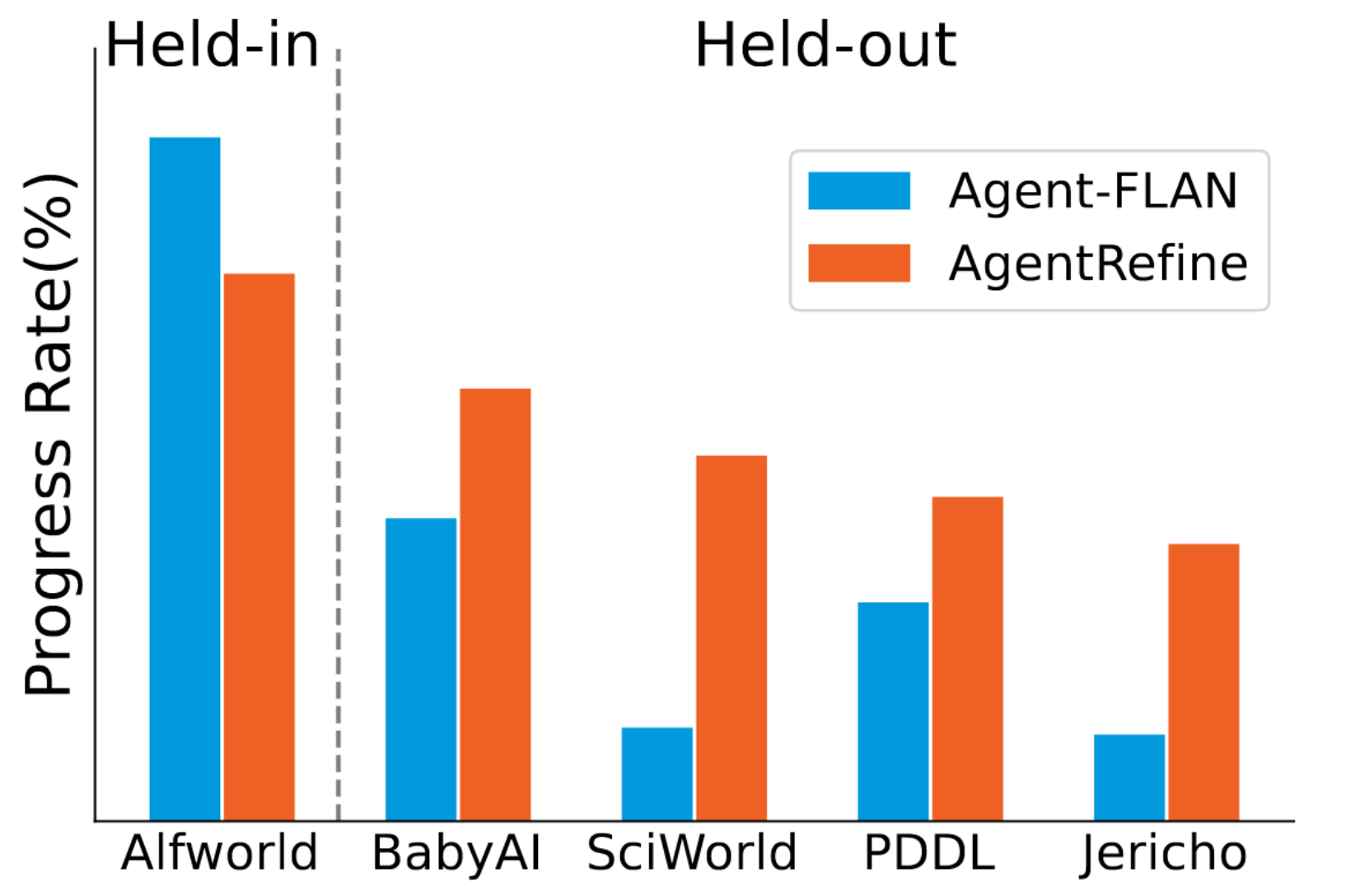
(Left) In Jericho, Agent-FLAN mistakenly believes it is not in the cell and attempts to go to cell. After failing, it chooses to check valid actions. Although check valid actions is a correct choice, Agent-FLAN does not correct its erroneous decision based on the returned results and repeats the go to cell and check valid actions error loop. In contrast, AgentRefine, upon realizing its actions are not achieving the goal, tries various new methods instead of endlessly repeating previously tried incorrect actions.
(Right) In Sciworld, Agent-FLAN ignores the hint in the Goal that the f ork is in the bedroom and chooses to search in the kitchen. Additionally, Agent-FLAN, having memorized the Alfworld dataset, attempts to output locations can only be found in Alfworld (drawer, countertop, and the action format go to {place}), which do not exist in SciWorld. Conversely, AgentRefine can clearly find the thermometer and decide to go bedroom to search for the f ork. After go bedroom fails, it decides to go hallway based on several rounds of observation. In T hought 6, although AgentRefine mistakenly believes it cannot reach the bedroom, its judgement shows it can revise its decisions using short-term memory (from turn 2). When Observation 6 provides clear information about the bedroom, AgentRefine can correct its wrong decision in T hought 6 and reach the bedroom. This indicates that AgentRefine's improvement in results is not due to memorizing prior knowledge from training data but rather its ability to efficiently utilize and integrate multiple key pieces of information from short-term memory to correct errors in historical decisions.